Image and Video Compression
Video coding is the process of reducing the huge volume of video data to a small number of bits. High coding efficiency reduces the bandwidth required for video streaming, and the memory required to store the video data on electronic devices, while maintaining the fidelity of the decompressed video signal. In recent years, deep learning has successfully tackled fundamental computer vision tasks such as image classification, object detection and semantic segmentation. Nevertheless, research achievement in deep learning-based video coding is still in its infancy. In our project, we propose a deep learning-based video
compression framework which uses both intra- and inter-frame correlations. First, we train an intra-frame compression
network to compress all the odd frames. Second, we train a prediction network that predicts each even frame by the decoded
preceding and next odd frames, implicitly exploring inter-frame motions. Finally, a residue compression network is trained
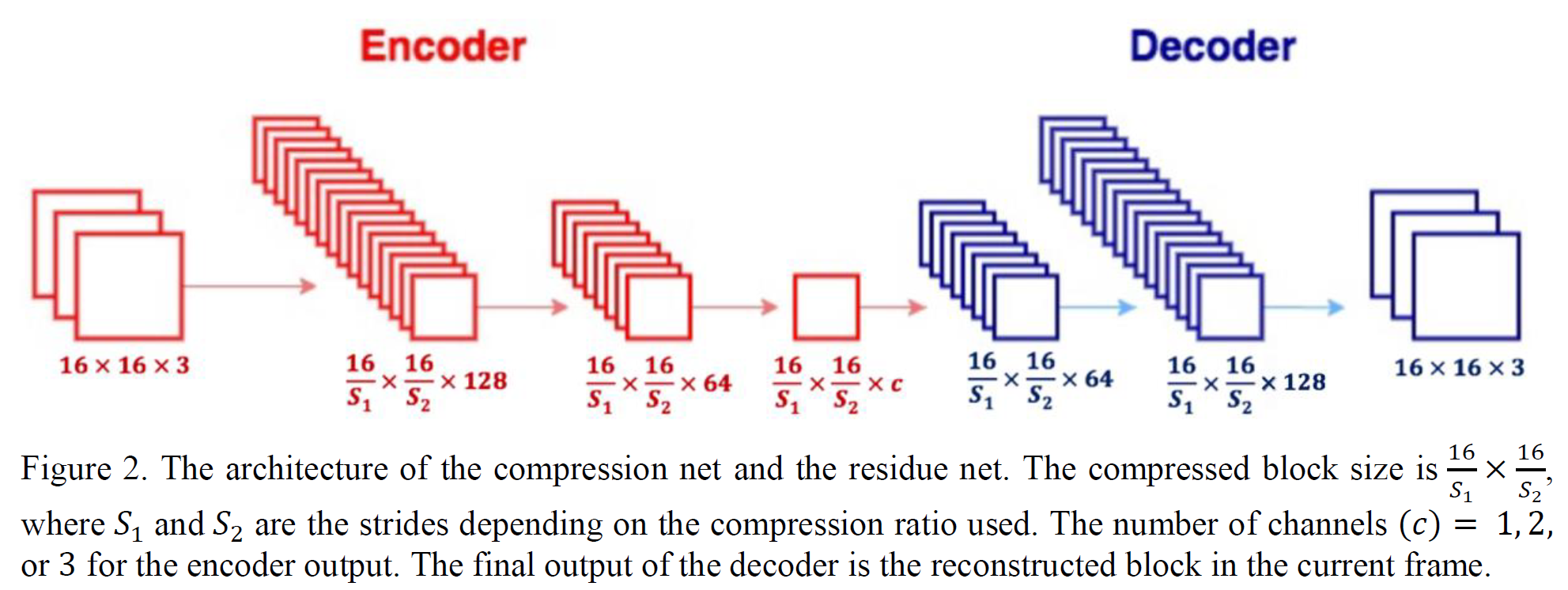
to compress the residue between the target even frame and its prediction. Our architecture is shown in Fig. 1, in which the upper layer is the intra-frame compression network, the middle layer is the motion-aware frame prediction layer, and the lower layer is the residue compression layer. The network structure of the intra-frame compression and residue-frame compression network can be found in Fig. 2.